

Visualisierung mit Graphen
16.02.2017 Michael Mosmann
Visualisierung mit Graphen
In jedem Softwareprojekt werden Daten verarbeitet. Dabei werden Listen gefiltert, Einträge gruppiert, sortiert, aggregiert. Überraschend oft gibt es Anwendungsfälle, wo ermittelt werden muss, ob und wie Dinge miteinander verbunden sind.
- Hat der Nutzer die notwendigen Rechte?
- In welcher Reihenfolge müssen Komponenten initialisiert werden?
- Läuft ein Prozess gerade im Kreis?
Diese Fragestellungen können mit Graphen beantwortet werden.
Während es für das Sortieren von Listen, das Gruppieren von Einträgen und anderen klassischen Datenverarbeitungsprozessen in den Java-Standardbibliotheken entsprechende Datenstrukturen gibt, fehlen entsprechende Funktionalitäten für die Verarbeitung von Graphen.
Wo es in der Standardbibliothek mangelt, springen andere Projekte ein, um die Lücken zu füllen: Während JavaSlang sich auf die klassischen Datenstrukturen konzentriert, findet man z.B. bei Google Guava neben Immutable-Versionen für Listen und Maps sogar Implementierungen, um mit Graphen zu arbeiten.
Als wir in einem Projekt auf ein Graph-Problem gestoßen sind, haben wir auf JGrapht benutzt. Zu diesem Zeitpunkt unterstützte Google Guava noch keine Graphen.
Wozu brauche ich denn einen Graph?
Um diese Fragen beantworten zu können, müssen wir uns erst einmal von einer anderen Seite dem Problem nähern. Betrachten wir, was man mit einem Graphen üblicherweise beantworten kann. Stark vereinfacht gesagt, kann man über einen Graphen ausdrücken, wie man von A nach B kommt (wer es genauer wissen möchte, kann gern bei Wikipedia nachlesen).
Natürlich ist ein Graph mit nur zwei Punkten recht uninteressant. Spannender wird es, wenn die Anzahl der Knoten (A, B, ...) und die Anzahl der Kanten (Verbindungen zwischen Knoten) größer werden. Dann ergeben sich fast automatisch zwei Problemstellungen:
- Komme ich von A nach Z?
- Wie komme ich am schnellsten von A nach Z?
- Gibt es Zyklen (läuft man im Kreis)?
Und genau diese Fragen kann man mit Hilfe von Graph-Bibliotheken beantworten.
Anwendungsfall aus der Praxis: Löschen eines Nutzers aus der Datenbank
In einem Projekt kam die Anforderung auf, dass man Nutzerdaten aus der Datenbank löschen können muss. Da die Anwendung selbst nicht mehr weiter betrieben wurde, sollte das Löschen der Nutzerdaten direkt auf Datenbankebene erfolgen. Die Informationen über die Abhängigkeiten zwischen den verschiedenen Tabellen lag nur zum Teil in der Datenbank selbst vor (Foreign Key-Informationen). Eine große Herausforderung bestand darin, dass man aus dem Anwendungscode die Beziehungsinformationen extrahieren musste. Da die Anwendung sehr groß war, konnten wir nicht den ganzen Code sichten und die Informationen zusammentragen. Wir mussten also die Lücken finden, die in unserem Modell fehlten. Doch wie findet man die Nadel im Heuhaufen?
Das Grundproblem
Im Idealfall ist das Löschen von Datenbankeinträgen sehr einfach. Man wählt den entsprechenden Eintrag aus und löscht diesen. Wenn es aber darum geht, alle mit einem Nutzer in Beziehung stehenden Informationen zu löschen, wird das Problem um einiges umfangreicher. Das hat mindestens zwei Gründe:
- Nicht immer sind alle fachlichen Relationen auch technisch in einer Datenbank
abgebildet (in dem Projekt gab es nicht immer entsprechende Foreign Keys) - Normalisierte Daten erschweren das Löschen. Teilen sich zwei Datensätze
einen referenzierten Datensatz, kann der erst gelöscht werden, wenn beide gelöscht wurden.
Außerdem könnte jemand auf die Idee gekommen sein, Zyklen in das Datenmodel einzubauen (das klappt nur, wenn die Spalte mit dem Foreign Key auch Null-Werte zulässt). Das war in dem Projekt tatsächlich der Fall.
Wie fängt man an?
Die erste naive Hoffnung war, dass man nur den einen Datensatz des Nutzers löschen muss und dann keine Daten des Nutzers mehr gefunden werden können. Dieser Ansatz stellte sich sehr schnell als unzureichend heraus. Die Lösung war nun erwartbar nicht mehr trivial. Mit folgenden Vorraussetzungen und Einschränkungen mussten wir arbeiten:
- Das Löschen muss ohne den Applikationscode funktionieren, denn das Löschen
muss auch noch in 10 Jahren möglich sein. - Es stehen die Informationen (Foreign Key, Metadaten, etc) aus der Datenbank zur Verfügung.
- Fehlende Beziehungen kann man aus dem Anwendungscode extrahieren.
Um uns einen ersten Überblick zu verschaffen, haben wir die Foreign Key-Informationen aus der Datenbank extrahiert. Dabei wurde schnell klar, dass man mit diesen ungefilterten Informationen ohne Weiteres keinen "Überblick" bekommt, denn es gab sehr viele Tabellen mit sehr vielen Beziehungen.
Zu diesem Zeitpunkt war klar, dass wir das ganze irgendwie grafisch darstellen müssen. Und es wurde offensichtlich, dass es um ein Graph-Problem ging.
Vorarbeit
Nach kurzer Suche haben wir uns für JGrapht entschieden, da die Bibliothek alle notwendigen Funktionen bereitstellt und einfach zu benutzen ist. Da unser Projekt Maven als Build-Tool benutzt, haben wir folgende Dependencies in unsere pom.xml aufgenommen.
<dependency>
<groupId>org.jgrapht</groupId>
<artifactId>jgrapht-core</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency></p>
<!-- immutables org -->
<dependency>
<groupId>org.immutables</groupId>
<artifactId>value</artifactId>
<version>${immutables.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.immutables</groupId>
<artifactId>builder</artifactId>
<version>${immutables.version}</version>
<scope>provided</scope>
</dependency>
...
<properties>
<immutables.version>2.4.2</immutables.version>
</properties>Die verwendeten Bibliotheken erfüllen folgende Funktion:
- jgrapht-core: das ist die Graph-Bibliothek
- guava: Immutable-Implementierung für das Collection-Api
- org.immutables.*: erzeugt Immutable-Implementierungen von z.B. Interfaces (inkl. equals und hashCode)
Datentypen
Da die Graph-Bibliothek die Gleichheit von Ecken und Kanten anhand des Ergebnisses von equals()/hashCode() ermittelt, benötigen wir ein paar Datentypen, damit wir die Informationen gut ablegen können und nicht immer mit zusammengebauten Strings arbeiten müssen. Die meiste Arbeit nimmt uns hier die Immutables.org-Bibliothek ab. Da die Möglichkeiten sehr umfangreich sind, verweise ich auf die Webseite des Projektes (https://immutables.github.io/), wo man nachlesen kann, wie das alles funktioniert.
In unserem Beispiel verwenden wir sehr stark vereinfachte Datentypen. Eine Tabelle in einer Datenbank liegt z.B. in einem Schema, sodass das Table-Interface mehr als nur den Namen als Attribut bereithalten müsste. Um später für die Darstellung zu einer lesefreundlichen Beschreibung der Tabelle zu gelangen, haben wir hier symbolisch die Methode asLabel() implementiert. Die @Auxiliary-Annotation sorgt dafür, dass die Methode nicht als Attribut in die Implementierung von hashCode(), equals() und toString() einfließt.
Fangen wir mit einer Tabelle an:
import org.immutables.value.Value;
import org.immutables.value.Value.Auxiliary;
import org.immutables.value.Value.Parameter;</p>
@Value.Immutable
public interface Table {
@Parameter
String name();
@Auxiliary
default String asLabel() {
return name();
}
public static Table of(String name) {
return ImmutableTable.of(name);
}
}So beschreiben wir eine Spalte in einer Tabelle:
@Value.Immutable
public interface TableColumn {
@Parameter
Table table();</p>
@Parameter
String column();
@Auxiliary
default String asLabel() {
return table().name()+":"+column();
}
public static TableColumn of(Table table, String column) {
return ImmutableTableColumn.of(table, column);
}
}Und dann kann man ein Foreign Key so definieren:
import org.immutables.value.Value;
import org.immutables.value.Value.Parameter;</p>
@Value.Immutable
public interface ForeignKey {
@Parameter
TableColumn source();
@Parameter
TableColumn destination();
public static ForeignKey of(TableColumn source, TableColumn destination) {
return ImmutableForeignKey.of(source, destination);
}
}Graph Wrapper
Wir schreiben uns einen Wrapper für die Graph-Klasse, um die Implementierungsdetails der Graph-Bibliothek zu verstecken:
import org.immutables.value.Value;
import org.immutables.value.Value.Parameter;
import org.jgrapht.DirectedGraph;
import org.jgrapht.alg.DijkstraShortestPath;
import org.jgrapht.graph.DefaultDirectedGraph;
import org.jgrapht.graph.DefaultEdge;</p>
import com.google.common.collect.FluentIterable;
import com.google.common.collect.ImmutableSet;
public class Graph<T> {
private final DirectedGraph<T, DefaultEdge> graph=new DefaultDirectedGraph<>(DefaultEdge.class);
public DefaultEdge addEdge(T a, T b) {
graph.addVertex(a);
graph.addVertex(b);
return graph.addEdge(a, b);
}
public boolean addVertex(T v) {
return graph.addVertex(v);
}
public boolean containsEdge(T a, T b) {
return graph.containsEdge(a, b);
}
public boolean containsVertex(T v) {
return graph.containsVertex(v);
}
public boolean hasPath(T a, T b) {
return DijkstraShortestPath.findPathBetween(graph, a, b) != null;
}
public ImmutableSet<T> vertexSet() {
return ImmutableSet.copyOf(graph.vertexSet());
}
public ImmutableSet<Edge<T>> edgeSet() {
return FluentIterable.from(graph.edgeSet())
.transform(e -> (Edge<T>) ImmutableEdge.of(
graph.getEdgeSource(e), graph.getEdgeTarget(e)))
.toSet();
}
@Value.Immutable
interface Edge<T> {
@Parameter
T source();
@Parameter
T destination();
}
}Datenextraktion und Graph
Wenn man die Foreign Key-Informationen aus der Datenbank extrahiert hat, kann man daraus bereits einen einfachen Graph erzeugen. Da der Prozess bei uns sehr viel Zeit in Anspruch genommen hat, haben wir diese Informationen in eine Datei serialisiert und dann nur noch auf dem "Snapshot" gearbeitet. Dazu haben wir auf die Json-Unterstützung der Immutables.org-Bibliothek zurück gegriffen. Wir haben die Daten aus der Datenbank in unsere Datenstruktur gelesen und als Json serialisiert. Später haben wir die Daten aus dem Json in unsere Datenstruktur zurück serialisert.
Diese Datenstruktur entsprach vereinfacht Iterable<ForeignKey>. Aus der Liste von ForeignKeys einen Graphen zu erstellen, gestaltete sich dann sehr einfach:
private static Graph<Table> graphOf(Iterable<ForeignKey> foreignKeys) {
Graph<Table> graph = new Graph<>();
foreignKeys.forEach(fk -> {
graph.addEdge(fk.source().table(), fk.destination().table());
});
return graph;
}
Damit hat man einen Graphen, bei dem es für jede Foreign Key-Beziehung zwischen Tabellen eine Kante im Graph gibt. Damit kann man erste Fragen beantworten, z.B. ist Tabelle A von C abhängig, oder Tabelle C von Tabelle E?
ImmutableList<ForeignKey> foreignKeysFromDatabase = foreignKeysFromDatabase();</p>
Graph<Table> graph = graphOf(foreignKeysFromDatabase);
Table tableA = Table.of("A");
Table tableC = Table.of("C");
boolean thereIsAPathFromAToB = graph.hasPath(tableA, tableC);
Table tableE = Table.of("E");
boolean thereIsNoPathFromCToE = graph.hasPath(tableC, tableE);Visualisierung
Die richtigen Fragen kann man aber erst stellen, wenn man das Problem verstanden hat. Wir hatten nun eine Unmenge von Beziehungen zwischen Tabellen, aber immer noch keinen Anhaltspunkt dafür, was noch fehlt. Was helfen würde, wäre eine grafische Darstellung der Informationen, die wir bereits haben. Natürlich gibt es Datenbanktools, die einem diese Funktionalität bieten. Allerdings scheiterte das zum einen daran, dass natürlich nur die Informationen aus der Datenbank zur Verfügung standen und man die anderen Informationen nicht einpflegen konnte. Zum anderen war aber immer die Menge an Relationen so groß, dass eine Darstellung nicht möglich oder unbrauchbar war.
Wir mussten also unsere Daten irgendwie visualiseren. Da ich bereits einige Erfahrungen mit Graphviz gemacht habe, wusste ich, dass man damit sehr schnell zu einem Ergebnis kommen würde. Die am Anfang erwähnte Abbildung eines Graph wurde z.B. aus dieser Textdatei generiert:
digraph {
A -> B;
B -> C;
A -> C;
}
Dieses Beispiel zeigt, mit welchen einfachen Mitteln man zu einer Visualiserung mit Graphviz kommen kann. Auch wenn das Beispiel so aussieht, als ob man da mal schnell eine Funktion schreibt, die so eine Textdatei erzeugen kann, empfiehlt es sich, gleich etwas mehr Energie in diesen Aspekt zu investieren. Auf diese Weise kann man das Ergebnis schnell an die eigenen Wünsche anpassen und Probleme wie z.B. fehlende Anführungszeichen beim ersten Auftreten nachhaltig lösen. Eine einfache Implementierung für die Erzeugung eines Dot-Files (Dot ist ein Programm des Graphviz-Paketes, mit dem dieser Graph generiert wurde) könnte so aussehen:
import java.util.Map;
import java.util.function.BiFunction;
import java.util.function.Function;
import org.immutables.builder.Builder.Parameter;
import org.immutables.value.Value;
import org.immutables.value.Value.Default;
import com.google.common.base.Joiner;
import com.google.common.collect.FluentIterable;
import com.google.common.collect.ImmutableMap;
@Value.Immutable
public abstract class GraphAsDot<T> {
@Parameter
public abstract String name();
@Parameter
public abstract Function<T, String> vertexAsLabel();
@Default
public Function<T, ? extends Map<String, String>> vertextAttributes() {
return t -> ImmutableMap.of();
}
@Default
public BiFunction<T, T, ? extends Map<String, String>> edgeAttributes() {
return (a,b) -> ImmutableMap.of();
}
public String asDot(Graph<T> graph) {
StringBuilder sb=new StringBuilder();
sb.append("digraph ").append(name()).append("{\n")
.append("\trankdir=LR;\n");
graph.vertexSet().forEach(v -> {
sb.append("\t").append(quote(vertexAsLabel().apply(v)))
.append(asAttributes(vertextAttributes().apply(v)))
.append(";\n");
});
sb.append("\n");
graph.edgeSet().forEach(e -> {
sb.append("\t")
.append(quote(vertexAsLabel().apply(e.source())))
.append(" -> ")
.append(quote(vertexAsLabel().apply(e.destination())))
.append(asAttributes(edgeAttributes().apply(e.source(), e.destination())))
.append(";\n");
});
sb.append("}\n");
return sb.toString();
}
private String asAttributes(Map<String, String> map) {
if (map.isEmpty()) return "";
return "[ "+FluentIterable.from(map.entrySet())
.transform(e -> e.getKey()+"="+quote(e.getValue()))
.join(Joiner.on(", "))+"]";
}
private String quote(String source) {
return "\""+source+"\"";
}
public static <T> ImmutableGraphAsDot.Builder<T> builder(String name, Function<T, String> nodeAsLabel) {
return ImmutableGraphAsDot.builder(name, nodeAsLabel);
}
}Damit können wir aus unserem Graph aus Foreign Key-Beziehungen wie folgt in eine Dot-Datei erzeugen:
ImmutableList<ForeignKey> foreignKeysFromDatabase = foreignKeysFromDatabase();
Graph<Table> graph = graphOf(foreignKeysFromDatabase);
String tableGraphAsDot = GraphAsDot.builder("Tabellen", Table::name)
.build()
.asDot(graph);Was dieses Ergebnis erzeugt:
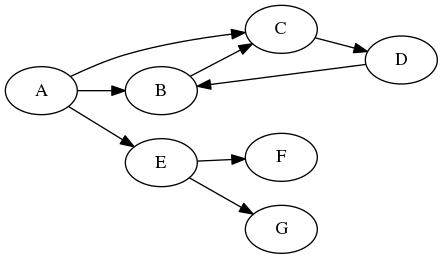
Anhand der Grafik bekommt man einen guten ersten Eindruck der Struktur. Was man aber noch nicht sieht, sind die Informationen, die in den Foreign Key-Beziehungen stecken. Dazu müssen wir einen anderen Graphen erzeugen.
Visualisierung der Foreign Key-Beziehungen
Für dieses Beispiel schaffen wir uns eine Hilfsklasse,mit der wir eine Typeinschränkung über voneinander unabhängige Typen zur Laufzeit sicherstellen können:
import org.immutables.value.Value;
import org.immutables.value.Value.Parameter;
import com.google.common.base.Optional;
import com.google.common.base.Preconditions;
import com.google.common.collect.ImmutableSet;
import com.google.common.collect.Iterables;
@Value.Immutable
public abstract class OneOf<T> {
@Parameter
protected abstract T value();
@Parameter
protected abstract ImmutableSet<Class<?>> types();
public <X> Optional<X> instanceOf(Class<X> type) {
if (type.isInstance(value())) {
return Optional.of((X) value());
}
return Optional.absent();
}
@Value.Immutable
public abstract static class OneOfBuilder {
protected abstract ImmutableSet<Class<?>> types();
public <T> OneOf<T> with(T instance) {
Preconditions.checkArgument(Iterables.any(types(),
t -> t.isInstance(instance)),
"unknown type % (not in %s)",instance.getClass(), types());
return ImmutableOneOf.of(instance, types());
}
}
public static OneOfBuilder types(Class<?> ... types) {
return ImmutableOneOfBuilder.builder().addTypes(types).build();
}
}Wir erzeugen uns ein weiteres Mal den Graph aus den Foreign Key-Informationen:
ImmutableList<ForeignKey> foreignKeysFromDatabase = foreignKeysFromDatabase();
Graph<Table> graph = graphOf(foreignKeysFromDatabase);
Table tableToDelete = Table.of("C");
Dann erzeugen wir mit Hilfe des ersten Graph einen zweiten, bei dem geprüft wird, ob es Verbindungen zu der zu löschenden Tabelle("C") gibt:
Graph<OneOf<?>> foreignKeyGraph = new Graph<>();
OneOfBuilder oneOfBuilder = OneOf.types(Table.class, TableColumn.class);
foreignKeysFromDatabase.forEach(fk -> {
if (graph.hasPath(fk.destination().table(), tableToDelete)) {
OneOf<Table> sourceTable = oneOfBuilder.with(fk.source().table());
OneOf<TableColumn> sourceColumn = oneOfBuilder.with(fk.source());
OneOf<TableColumn> destinationColumn = oneOfBuilder.with(fk.destination());
OneOf<Table> destinationTable = oneOfBuilder.with(fk.destination().table());
foreignKeyGraph.addEdge(sourceTable, sourceColumn);
foreignKeyGraph.addEdge(sourceColumn, destinationColumn);
foreignKeyGraph.addEdge(destinationColumn, destinationTable);
}
});Die Visualiserung wird jetzt etwas komplizierter, weil wir verschiedene Attribute für die Darstellung vergeben wollen. Dazu definieren wir uns ein paar Konstanten, die wir dann entsprechend benutzen. Welche Möglichkeiten Graphviz bietet kann man sich entweder über die verschiedenen Beispiele erarbeiten oder in der Dokumentation nachlesen:
private static final ImmutableMap<String, String> DOTTED_GREY_LINE = ImmutableMap.of("style","dotted","color","grey");
private static final ImmutableMap<String, String> GREEN_RECTANGLE = ImmutableMap.of("shape", "rectangle","color","#006000","fontcolor","#006000","fillcolor","#c0f0c0", "style", "filled");
private static final ImmutableMap<String, String> GREY_RECTANGLE = ImmutableMap.of("shape", "rectangle","color","grey","fontcolor","grey");
private static final ImmutableMap<String, String> RECTANGLE = ImmutableMap.of("shape", "rectangle");
Nun erzeugen wir die Dot-Datei:
String tableGraphAsDot = GraphAsDot.builder("ForeignKeys", (OneOf<?> t) -> {
return t.instanceOf(Table.class)
.transform(Table::asLabel)
.or(t.instanceOf(TableColumn.class)
.transform(TableColumn::asLabel))
.or("?");
}).vertextAttributes(v -> {
return v.instanceOf(Table.class)
.transform(tab -> {
if (tab.equals(tableToDelete)) {
return GREEN_RECTANGLE;
}
return GREY_RECTANGLE;
}).or(v.instanceOf(TableColumn.class)
.transform(col -> RECTANGLE))
.or(ImmutableMap.of());
}).edgeAttributes((a,b) -> {
boolean aIsTable = a.instanceOf(Table.class).isPresent();
boolean bIsTable = b.instanceOf(Table.class).isPresent();
if (aIsTable || bIsTable) {
return DOTTED_GREY_LINE;
};
return ImmutableMap.of();
})
.build()
.asDot(foreignKeyGraph);
Das Ergebnis sieht dann wie folgt aus:

Der Graph sah im Projekt natürlich nicht so einfach aus. Aber über die verschiedenen Darstellungsmöglichkeiten konnten wir sehr schnell ermitteln, an welchen Stellen wir im Anwendungscode nachsehen mussten, um die fehlenden Beziehungen in unserem Modell zu ergänzen. Wie man dann aus dem fertigen Modell zu einer Anwendung kommt, die einen Nutzer aus der Datenbank löscht ist eine andere Geschichte.
Fazit
Die Visualisierung der Beziehungen zwischen den Tabellen in der Datenbank und die Möglichkeit, basierend auf den selben Daten ganz unterschiedliche Graphen zu erstellen und diese entsprechend in eine Darstellung zu überführen, half uns in dem Projekt, die Fragen nach den Abhängigkeiten zwischen den Tabellen beim Löschen eines Nutzers zu beantworten. Da man mit den Ergänzungen aus den Erkenntnissen der Codeanalyse die Darstellung immer wieder neu generieren konnte, waren wir in der Lage, sehr schnell neue Lücken in unserem Modell zu erkennen und entsprechend zu schließen.
Gerade in der Analysephase können graphische Darstellungen auch komplexe Sachverhalte gut transportieren. Der Aufwand für das Visualisieren ist überraschend gering und lässt sich zu einem hohen Grad wiederverwenden. Außerdem wird man feststellen, dass man öfter als gedacht ein Problem mit einem Graph elegant lösen kann.
Daher findet man den Code in leicht abgewandelter Form und um ein paar weitere (wie ich finde nützliche) Funktionen ergänzt hier: Flapdoodle Graph. Wer bereits Guava benutzt und nicht noch eine Dependency mehr in seinem Projekt gebrauchen kann, sollte sich die Graph-Funktionen anschauen, die Guava bereitstellt: Graphs, Explained
Wer an Graphviz gefallen gefunden hat, sollte sich auch dieses Tool ansehen: PlantUML. Da werden wie bei Graphviz aus einfachen Textbeschreibungen komplexe Ablaufdiagramme.